

This post was originally published on this site.
I’ve been working in the customer support outsourcing space since 2021, and the shift we’ve seen over the last year is unlike anything else in such a short span.
The current narrative around AI is almost exclusively about “wins”: faster response times, greater operational efficiency, and lower costs. And yes, those results are possible. Nonetheless, in my experience, AI only hits those benchmarks under very specific conditions: it requires rigorous training and a high-quality data foundation. I wanted to share some thoughts on what it actually takes to get those results.
What is the State of AI Implementation in eCommerce Now?
Before we start discussing the technical issues of current AI implementation, let’s just take a quick look at the sheer numbers.
- AI in eCommerce is already a big business, worth about $8.6 billion in 2025. By 2032, the market is expected to more than double, reaching $22.6 billion, with steady growth year over year.
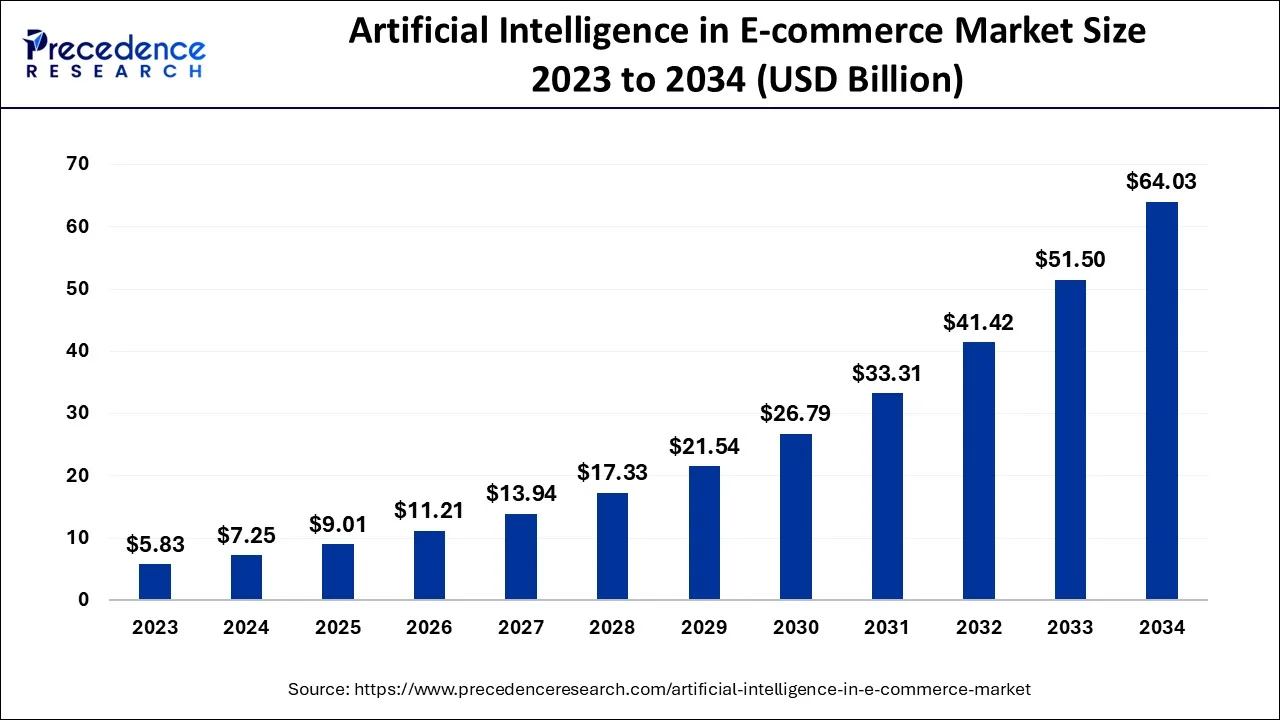
Source: Zoting, S. (2024, December 16). Artificial intelligence in e-commerce market size, report by 2034. https://www.precedenceresearch.com/artificial-intelligence-in-e-commerce-market
- 78% of organizations are currently using AI in at least one of their business operations.
- According to Adobe Digital Insights, traffic from generative AI to U.S. retail websites skyrocketed — growing 4,700% back in July 2025.
- The global conversion rate in eCommerce has reached 3.34% in 2025 as more businesses started to adopt Artificial Intelligence.
- Retail and ecommerce studies attribute double‑digit improvements in CSAT, NPS, and resolution speed to AI‑assisted service, with FusionCX 2025 summary noting 12% higher NPS and 27% faster resolutions for hybrid human‑plus‑AI models.
- AI-driven conversations became especially effective at attracting new buyers, with 64% of AI-powered sales coming from first-time shoppers.
AI-Powered Ecommerce Support Fails Without Unified Data
As you can see, eCommerce brands have already spent a lot of time, money, and hope on AI in customer support. Chatbots to handle WISMO tickets, AI recommendations to boost repeat purchases, agent assist tools to speed things up — we’ve seen it all. And honestly, we believed in that promise too. At EverHelp, for instance, we didn’t just integrate AI into our workflows, but built and implemented our own AI support tool from the ground up.
What we learned pretty quickly is this: when AI fails in customer support, it’s rarely because the technology isn’t good enough. The real issue is the data behind it. In fact, 73% of data leaders note “data quality and completeness” as the primary obstacle to AI success, ranking it above model accuracy or computing costs. Most eCommerce teams are asking AI to work with customer information that’s scattered across platforms — ecommerce engines, CRMs, help desks, marketing tools, payment systems — none of which tell the full story on their own. And what we’ve seen firsthand is inconsistent data limits AI’s impact and amplifies existing support problems.
As I’ve written before:
“One of the biggest risks isn’t just inefficiency. It’s “AI confidently giving wrong answers that harm the customer experience and damage trust when it doesn’t have solid data to work from.”
What Fragmented Customer Data Looks Like in Ecommerce
Walk into any eCommerce operation, and you’ll find customer information siloed across separate systems:
→ The ecommerce platform (Shopify, Magento, BigCommerce) tracks orders and browsing.
→ Your order management and inventory systems know what’s in stock and where shipments are.
→ The marketing stack (Klaviyo, Braze, Attentive) holds email opens, SMS opt-ins, and campaign responses. Loyalty programs live in yet another database.
→ Customer service platforms keep ticket history and interaction logs.
Each system evolved independently, each uses different customer IDs, and each updates on its own schedule.
The situation gets messier when brands layer on even more AI support tools:
- One vendor’s chatbot pulls from the knowledge base.
- Another does order lookup via API. Agent-assist reads help desk tickets, but not CRM notes.
- The search function indexes product pages but misses policy updates.
Each AI tool dips into only the subset of data its integration can access, blind to context sitting three systems away.
Everyday Symptoms at the Support Level
And all of this immediately shows at the support level. Agents open three screens to see a customer’s recent orders, check their return history, and verify subscription status. Chatbots confidently tell logged-in customers to “check your account” for information the bot itself can’t access. Customers constantly repeat their email address, order number, and issue description when they switch from chat to phone. And we all know that only those customers who experience low-effort interactions will return to make future purchases, yet these friction points persist everywhere.
You can see the fallout in the metrics almost immediately, too. Handle times stretch as agents bounce between systems, trying to assemble a complete picture of the customer. Transfers increase because the first interaction (whether handled by a bot or a human) didn’t have enough context to actually solve the problem. And when self-service answers don’t match what a live agent eventually says, customers stop trusting the system and escalate instead. It’s no surprise, then, that nearly 60% of customers say they’ll walk away from a brand after struggling to get an issue resolved.
How Fragmented Data Cuts The Efficiency of AI in Customer Support in Half
However, poor data doesn’t just slow things down, but fundamentally limits what your AI can accomplish. That frustrating gap between a slick pilot demo and what happens once the system hits real customers? In most cases, it’s not because the model failed. It’s because the data beneath it was never up to the job, and below, we will discuss a few key examples of just that.
Weak Personalization and Irrelevant Responses
In the modern world, personalization is becoming key to success. And AI customer support tools need complete customer profiles to deliver personally relevant responses. All of it matters:
- preferences
- order history
- previous issues
- support tickets
- return patterns
- communication opt-ins.
Thus, when profiles are incomplete or scattered, the AI resorts to generic scripts. It suggests products that the customer has already bought. It recommends the troubleshooting steps they tried last week in a different channel. It doesn’t understand that someone opted out of promotional emails but still wants transactional updates.
Inconsistent Answers Across Channels
Ecommerce brands often run multivendor support stacks:
- The email triage system uses one dataset and schema.
- The chatbot pulls from another.
- Agent assist tools draw from a third.
When a customer asks about their subscription via chat, gets escalated to email, and then calls in, each channel sees partial information formatted differently. The bot says the subscription renews on the 15th (reading the original signup date). The email team says it renews on the 20th (checking the modified schedule). The phone agent sees both entries but doesn’t know which is current.
This isn’t a hypothetical. Large DTC brands regularly field complaints about “your system saying two different things.” When there’s no clear system of record, customer service automation creates new problems instead of solving existing ones. Customers just stop believing automated responses and demand human escalation. In the end, this just defeats the efficiency gains AI promises.
Slower Resolution and Higher Effort for Customers
When data is missing or outdated, agents end up asking questions that should be automatic. Stale records trigger pointless identity checks. Manual lookups eat up the time AI was supposed to save. Companies with strong data integration achieve 10.3x ROI from AI initiatives, compared with 3.7x for those with poor connectivity. But it’s precisely because they have unified data that lets AI resolve issues end-to-end rather than punting to humans.
But fragmented data creates a second, sneakier problem: debugging. When a chatbot gives bad info, which system caused it? When Agent Assist recommends the wrong article, where did the context break down? Ops teams end up wasting weeks chasing symptoms because they can’t trace the problem back to the source. And every time you can’t A/B test reliably or track results across the full support journey, model improvements crawl along at a frustrating pace.
What Does It Mean For Businesses?
The first thing you’ll notice when data is scattered will be revenue leaks. Especially in the upsell and cross-sell sections:
- AI-driven upsell recommendations usually fire at the wrong moment because the system doesn’t realize a customer just started a return.
- Cross-sell suggestions can just push items that are out of stock because inventory isn’t synced with the recommendation engine.
But even promotions go sideways, as customers frustrated with a delayed order might get emails offering expedited shipping on their next purchase.
In 2024, 45% of consumers said they switched brands because of poor customer service. Naturally, when support can’t resolve issues quickly, customers don’t stick around. Cart abandonment also spikes, mostly when live chat can’t answer pre-purchase questions without transferring you to another department. Subscription cancellations rise when billing problems take three touchpoints to fix instead of one. Every friction point hits the bottom line, making your revenue just slip away.
Operational Inefficiency and AI ROI Risk
The same data fragmentation that drives revenue leaks also creates serious operational issues:
- Contact volume per issue increases when resolution requires multiple touchpoints.
- Escalation rates rise because frontline AI and agents lack the data to close tickets.
- Rework multiplies when one channel partially resolves an issue, and the next has to start over.
It has been proven that 70-85% of AI projects fail to deliver meaningful ROI, and fragmented data is at the core of most failures.
Leadership teams often underestimate this risk. They see strong results in pilots run on clean, curated datasets and assume production will perform the same. But reality is messier: duplicates, missing fields, conflicting sources, and delayed updates abound. Your AI models are essentially operating in the dark, making decisions without the whole picture. And just like that, the expensive technology that offered so much promise is being held back by the same gaps that are driving revenue loss and customer frustration.
Building the Data Foundation for Effective AI Support
Start with a customer 360 model, not another bot. Before layering on more AI tools, unify your customer data. A real customer 360 provides a governed, near-real-time view of each shopper across every channel and lifecycle stage. That means identity resolution (recognizing the same person across devices and sessions), deduplication (merging scattered records), and standardizing core entities like customers, orders, products, and interactions.
You should think of it as building the base that your AI customer support workflow runs on. Without unified customer IDs, your chatbot won’t see order history when someone switches from email to chat. Without standardized product data, recommendations will break when SKUs don’t match between systems. And with no synchronized interaction logs, sentiment analysis customer support tools will miss context from previous channels. Let’s not forget that AI reads data literally. It can’t fill gaps or interpret ambiguity the way humans do.
But purchasing a CDP won’t allow you to declare victory. You will have to do much more extra work:
- mapping data flows
- establishing governance
- defining what “customer” means across systems
- and implementing processes that keep data clean as it moves.
Brands that treat this as a one-and-done integration project are setting themselves up to fail. You can only win if you bake data quality into your day-to-day operations. You will need to keep your records up to date, catch duplicates, and ensure the established formats actually make sense. That’s the only way you can stop AI from flailing and start seeing progressive improvement, month after month.
Extras to Consider: Data Quality, Governance, and Real-Time Signals
As was mentioned above, AI agents interpret data exactly as provided. Duplicates confuse matching algorithms. Missing fields trigger fallback logic that defaults to generic responses. Stale records send AI down paths that don’t reflect current reality. Data quality or availability remains the biggest obstacle for 77% of organizations implementing AI, larger than any technical or talent challenge.
Thus, to be able to benefit from AI in eCommerce, it’s necessary to implement automated data quality checks at ingestion. First, set thresholds:
- Flag order records without tracking numbers for review.
- Route customer profiles without communication preferences differently.
- Pause automation for inventory counts that haven’t updated in 24 hours.
Next, make sure every team speaks the same language. “Active subscriber” should mean the same thing in marketing, billing, and support. Finally, implement access controls that balance AI needs with privacy requirements.
Real-time data is critical for excellent customer service powered by AI. A customer’s current cart contents, live inventory, and active support tickets matter far more than knowing what they bought two years ago. Streaming updates from eCommerce and fulfillment systems let AI answer questions like “where’s my order?” without forcing agents to hop between multiple systems. Remember: omnichannel automation only works when every channel sees the same, up-to-the-minute information.
Practical Steps for Ecommerce Teams to Defragment Support Data
Theory is nice, but it’s the execution that wins. So, you’d better start with practical moves that deliver measurable improvement fast.
Map Your AI Use Cases to Data Requirements
Make a list of your most important AI customer support use cases: order status bots, returns automation, WISMO (Where Is My Order) deflection, proactive notifications, and so on. For each one, map out the data it actually needs and where that data is stored. Doing this exposes exactly where silos are slowing things down.
For example, if your chatbot only sees order placement data but needs real-time shipping updates, it’s no wonder it can’t answer “Where’s my package?” And when agent-assist tools don’t have a unified ticket history across email, chat, and phone, the suggestions they give will inevitably lack context. Here’s a quick look at what such a “map” may look like.
AI Use Cases Map
|
Use Case |
Required Data |
Current Blocker |
|---|---|---|
|
Order status bot |
Real-time shipping events, carrier tracking, warehouse updates |
Tracking data is stored in a separate OMS. Chatbot only sees order placement |
|
WISMO deflection |
Order details, tracking status, estimated delivery, issue history |
Fragmented across eCommerce platform, 3PL, and support tickets |
|
Returns automation |
Purchase history, return policy by product category, and current inventory |
Policy logic in a separate system from transaction data |
|
Proactive delay notifications |
Carrier exceptions, inventory shortages, customer preferences |
No unified view connecting fulfillment alerts to customer communication channels |
|
Agent assist recommendations |
Full ticket history, order context, previous resolutions, product details |
Each channel creates separate tickets. No cross-channel view |
Integration Patterns that Work in Practice
There are three main approaches that solve fragmentation differently.
- Customer Data Platforms (CDPs) aggregate profile and interaction data into a unified customer record that support systems can query.
- AI middleware layers sit between your support tools and backend systems, translating requests and normalizing responses on the go.
- Unified AI customer service platforms replace point solutions with integrated stacks that access data directly without copying everything into yet another database.
Of course, you should pick one of these based on your architecture and velocity needs. CDPs work well when customer profiles are the primary bottleneck, and it’s operational systems (orders, inventory) that update too frequently to replicate. Middleware helps when you’re locked into legacy systems that can’t be replaced, but that still need to feed modern AI tools. Unified platforms make sense for brands willing to consolidate vendors in exchange for tighter integration.
Here’s the key principle: don’t move data into new silos – access it where it already lives. Copying everything creates delays, sync troubles, and unnecessary storage costs. A composable architecture that analyzes source systems in real time keeps data fresh and integrations simpler. For example, when your chatbot checks an order status, it should pull directly from your OMS API instead of relying on a stale snapshot stored in a separate database.
Looking Ahead: Unified Data as a Competitive Moat for AI Support
Every ecommerce brand will eventually implement similar AI tools. ChatGPT-powered chatbots, Anthropic-backed agent-assists, and recommendation engines from established vendors – the technology sells out fast. What doesn’t commercialize is unified, well-governed customer data.
And the simple truth is, brands with complete customer views will be the ones delivering faster, more accurate support. Their AI systems will understand context across channels. Their agents will see full histories in seconds, without switching screens. Their automation will handle edge cases that others escalate. As AI models improve, data quality will be the binding constraint on performance. The best algorithm running on fragmented data will lose to a decent algorithm with unified context.
What is there more to say? We all should start treating data unification as a strategic investment, not IT overhead. Companies that fix data foundations now will gain more capable, trustworthy AI agents. And those that keep layering AI onto broken data pipelines will plateau, wondering why their sophisticated tools underperform simpler solutions at better-organized competitors. And the difference isn’t the AI. It’s what you feed it.